Building a Data Science AMI for AWS EC2
August 15, 2020
This page outlines the current AMI I use for data science projects on AWS EC2. I update this stack every couple of months when new versions of the base software are released. If any of these instructions aren’t clear or don’t work for you, please let me know (my contact info is on the homepage).
What’s included and why
- Amazon Linux 2
-
The AMI is built on Amazon Linux 2 which has a good selection of packages and is optimized for EC2. It’s compatible with CentOS / Redhat packages which is helpful for installing pre-compiled software like Rstudio Server. You can also add EPEL (see here for instructions) for access to a much broader range of packages.
- R 3.6.3 + Tidyverse
-
I use R for almost all my analysis, usually in conjunction with the tidyverse. Check out R for Data Science for a good introduction. The latest version of R is actually 4.0.2 but I prefer to wait for a .1 release before switching to a major new version so for now I am using 3.6.3.
- RStudio Server
-
The AMI uses the open-source version of Rstudio Server to provide a browser-based graphical interface to R running on EC2. Although Rstudio Server can support multiple users, I use it exclusively in single-user mode and don’t allow logins from the open internet; instead I just tunnel via ssh on port 8787.
- Python 3.7 + Pandas + Jupyter
-
Python 3.7 is the standard Python version that comes with Amazon Linux 2. I write quite a bit of Python code but usually for ETL jobs or shell scripts rather than analytical tasks (I prefer R for analysis). However, I always install Pandas and Jupyter as they are key tools for data science.
- Various utilities
-
These include the latest versions of Pandoc for processing markdown and Rmarkdown, jq for command-line JSON parsing, and the AWS CLI for interacting with AWS services. The version of the AWS CLI that comes with Amazon Linux 2 is quite old so I always install the latest version in a Python virtual environment so it can be updated more regularly.
How it’s built
The AMI is built using Packer. The intro documentation for Packer is
very thorough so I recommend starting there. The tutorial uses
aws_access_key and aws_secret_key variables
for authentication but I prefer to use a custom IAM role instead as it
is more secure (details
here).
The basic steps to build the AMI are:
- Spin up a small EC2 instance (e.g. t3.nano) to run the
packerbinary. Installpackeron that machine. - Create a
packer.jsontemplate file containing information on how to build the AMI (instance type, source AMI, commands to run, etc.) - Create an
install.shscript that is referenced inpacker.json. This install script will download and compile the necessary software. - Put both
packer.jsonandinstall.shin the same folder as yourpackerbinary and runpacker build packer.json. This spins up a new machine, copies theinstall.shscript over to it, runs the script and installs all the software, then saves the result as an AMI and terminates the build machine.
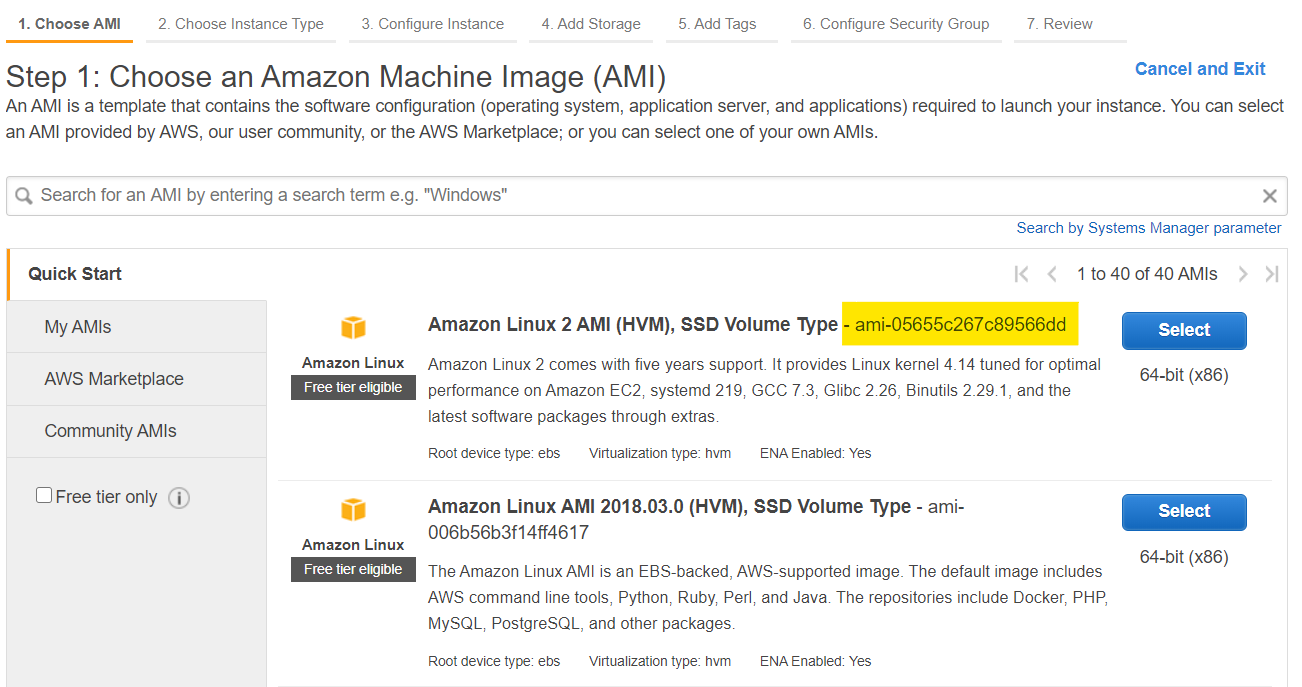
Here’s what I use in my template file packer.json. The
source_ami field should be updated to reference to the
latest version of the “Amazon Linux 2 AMI (HVM), SSD Volume Type” in
your region. You can find the AMI ID by launching a new instance and
looking in the console:
{
"builders": [
{
"type": "amazon-ebs",
"region": "us-west-1",
"source_ami": "ami-04e59c05167ea7bd5",
"instance_type": "c5.xlarge",
"ssh_username": "ec2-user",
"ami_name": "packer-datascience 20200613 {{timestamp}}",
"launch_block_device_mappings": [
{
"device_name": "/dev/xvda",
"volume_size": 20,
"volume_type": "gp2",
"delete_on_termination": true
}
]
}
],
"provisioners": [
{
"type": "file",
"source": "./install.sh",
"destination": "/tmp/"
},
{
"type": "shell",
"inline": [
"sudo bash /tmp/install.sh"
]
}
]
}And here’s the installation script install.sh run by
packer to build the AMI.
#!/bin/bash
# Update and install packages
yum update -y
yum install -y emacs pigz python3 git ImageMagick
# I use emacs as my editor and add some customizations to its site-start.el
echo "
(setq inhibit-splash-screen t)
(setq make-backup-files nil)
(setq-default indent-tabs-mode nil)
(electric-indent-mode -1)
" >> /usr/share/emacs/site-lisp/site-start.el
# To hold installation files
cd /tmp
# Install jq
curl -L https://github.com/stedolan/jq/releases/download/jq-1.6/jq-linux64 \
-o /usr/local/bin/jq
chmod a+rx /usr/local/bin/jq
# Install texlive. This is optional but will let you build pdfs from rmarkdown
# via latex which is a nice feature. A full texlive install takes 5GB+
# so I created a custom installation profile that only takes about 300MB
yum install -y perl-Digest-MD5
wget http://mirror.ctan.org/systems/texlive/tlnet/install-tl-unx.tar.gz
tar xvf install-tl-unx.tar.gz
cd install-tl-*
# Get profile. Note that we have selected to add symlinks to /usr/local/bin
# rather than adding to the PATH variable. This is because rstudio server
# open source version does not properly inherit the PATH variable from
# custom.sh, instead it sets its own path which DOES include /usr/local/bin.
echo '
selected_scheme scheme-custom
TEXDIR /usr/local/texlive/2020
TEXMFCONFIG ~/.texlive2020/texmf-config
TEXMFHOME ~/texmf
TEXMFLOCAL /usr/local/texlive/texmf-local
TEXMFSYSCONFIG /usr/local/texlive/2020/texmf-config
TEXMFSYSVAR /usr/local/texlive/2020/texmf-var
TEXMFVAR ~/.texlive2020/texmf-var
binary_x86_64-linux 1
collection-basic 1
collection-fontsrecommended 1
collection-latex 1
collection-latexextra 1
collection-latexrecommended 1
collection-metapost 1
collection-xetex 1
instopt_adjustpath 1
instopt_adjustrepo 1
instopt_letter 1
instopt_portable 0
instopt_write18_restricted 1
tlpdbopt_autobackup 1
tlpdbopt_backupdir tlpkg/backups
tlpdbopt_create_formats 1
tlpdbopt_desktop_integration 1
tlpdbopt_file_assocs 1
tlpdbopt_generate_updmap 0
tlpdbopt_install_docfiles 0
tlpdbopt_install_srcfiles 0
tlpdbopt_post_code 1
tlpdbopt_sys_bin /usr/local/bin
tlpdbopt_sys_info /usr/local/info
tlpdbopt_sys_man /usr/local/man
tlpdbopt_w32_multi_user 1
' > texlive-install.profile
./install-tl -profile texlive-install.profile
cd /tmp
rm -rf install-tl-*
# You can update this to the latest pandoc release as it becomes available
wget https://github.com/jgm/pandoc/releases/download/2.9.2.1/pandoc-2.9.2.1-linux-amd64.tar.gz
tar xvzf pandoc-2.9.2.1-linux-amd64.tar.gz --strip-components 1 -C /usr/local
rm -rf pandoc-2.9.2*
# Various development packages needed to compile R
yum install -y gcc gcc-gfortran gcc-c++
yum install -y readline-devel zlib-devel bzip2-devel xz-devel pcre-devel
yum install -y libcurl-devel libpng-devel cairo-devel pango-devel
# Install R
curl -O https://cran.r-project.org/src/base/R-3/R-3.6.3.tar.gz
tar xvf R-3.6.3.tar.gz
cd R-3.6.3
./configure --with-x=no --enable-R-shlib
# Use 4 cores to speed up build
make -j 4
make install
cd /tmp
rm -rf R-3.6.3*
# Install tidyverse
yum install -y libxml2-devel openssl-devel
echo 'options(repos = c(CRAN="https://cran.r-project.org/"))' >> /usr/local/lib64/R/etc/Rprofile.site
# Note the use of Ncpus = 4L. Since my packer build machine is a c5.xlarge
# it has 4 cpus so we'll use all of them to speed up compilation times.
/usr/local/bin/R -e 'install.packages(c("tidyverse"), Ncpus = 4L)'
# Add rstudio
/usr/local/bin/R -e 'install.packages(c("caTools", "bitops", "rprojroot"))'
curl -O https://download2.rstudio.org/server/centos6/x86_64/rstudio-server-rhel-1.3.959-x86_64.rpm
yum install -y --nogpgcheck rstudio-server-rhel-1.3.959-x86_64.rpm
rm -f rstudio-server-rhel-1.3.959-x86_64.rpm
# Will serve on port 8787 by default
echo www-address=127.0.0.1 >> /etc/rstudio/rserver.conf
echo rsession-which-r=/usr/local/bin/R >> /etc/rstudio/rserver.conf
# Other useful R packages
/usr/local/bin/R -e 'install.packages(c("corrplot", "plotly", "data.table", "slider"), Ncpus = 4L)'
# GNU Parallel (installs into /usr/local/bin). This is an awesome tool that
# lets you easily run commands across multiple CPUs.
# See https://www.gnu.org/software/parallel/
curl pi.dk/3/ | bash
rm -rf parallel-*
# GNU datamash. https://www.gnu.org/software/datamash/
# A command line tool for quick operations on text files.
yum install -y perl-Digest-SHA perl-Data-Dumper
wget https://ftp.gnu.org/gnu/datamash/datamash-1.7.tar.gz
tar xvf datamash-1.7.tar.gz
cd datamash-1.7
./configure
make
make install
cd /tmp
rm -rf datamash-1.7*
# xsv. https://github.com/BurntSushi/xsv
# A command line program for manipulating CSV files.
wget https://github.com/BurntSushi/xsv/releases/download/0.13.0/xsv-0.13.0-x86_64-unknown-linux-musl.tar.gz
tar xvf xsv-0.13.0-x86_64-unknown-linux-musl.tar.gz
mv xsv /usr/local/bin
rm xvf xsv-0.13.0-x86_64-unknown-linux-musl.tar.gz
# Add a recent version of the AWS CLI into its own virtual environment
python3 -m venv /opt/ve_awscli
# It's always useful to upgrade to the latest pip before installing
# any other packages
/opt/ve_awscli/bin/pip install --upgrade pip
/opt/ve_awscli/bin/pip install awscli
# The Amazon Linux 2 AMI comes with an old version of the AWS CLI
# which is on the the ec2-user's path at /usr/bin/aws.
# We'll put a symlink to our newly installed version of the AWS CLI
# into /usr/local/bin which is first in the $PATH variable and thus
# will give it precedence when run you run "aws" as the ec2-user.
# Note that when you run "aws" as the root user you will still run the
# old, system-installed version of the CLI since /usr/local/bin is not
# on the root's path
ln -s /opt/ve_awscli/bin/aws /usr/local/binUsing the AMI
Start up a machine using your new AMI and connect to it from your Mac or Windows computer using:
ssh -i <keyfile> -L 8787:localhost:8787 -L 8888:localhost:8888 ec2-user@<ip address>Those two -L commands tunnel ports 8787 (for Rstudio
Server) and 8888 (for Jupyter) from the EC2 machine to your local
computer. Once you are connected via ssh you can visit
localhost:8787 to log into Rstudio. Note that you will have
to have set a password for the ec2-user to log in. To do that, on your
EC2 machine do:
sudo passwd ec2-user
sudo rstudio-server restartWhen I want to run jupyter I always just install the latest version into a virtual environment in my home folder as the ec2-user.
python3 -m venv /home/ec2-user/ve_jupyter
/home/ec2-user/ve_jupyter/bin/pip install --upgrade pip
/home/ec2-user/ve_jupyter/bin/pip install jupyter pandas seabornThe you can start jupyter on your EC2 machine using:
~/ve_jupyter/bin/jupyter notebookAnd since you are tunneling port 8888 in your ssh session you can connect to jupyter in your browser by visiting the url that jupyter prints, which looks like:
http://localhost:8888/?token=XXXXXXXXXXXXXXXXXX